
Data Analyst roles require the ability to collect, process, and perform statistical analysis on large data sets. They often apply their technical skills alongside knowledge of business strategy to draw valuable insights. In a tech interview, questions targeting a data analyst position often test the applicant’s proficiency in data manipulation, statistical analysis, data visualization, and understanding of database systems. This blog post will delve into possible interview questions and suitable answers for aspiring data analysts, highlighting the nuances of big data handling and business data interpretation peculiar to the profession.
Machine Learning Fundamentals for Data Analysts
- 1.
What is machine learning and how does it differ from traditional programming?
Answer:Machine Learning (ML) represents a departure from traditional rule-based programming by allowing systems to learn from data. While the latter requires explicit rules and structures, ML algorithms can uncover patterns and make decisions or predictions autonomously.
Core Distinctions
-
Input-Output Mechanism:
- Traditional Programming: Takes known input, applies rules, and produces deterministic output.
- Machine Learning: Learns mappings from example data, generalizing to make predictions for unseen inputs.
-
Human Involvement:
- Traditional Programming: Rule creation and feature engineering often require human domain knowledge.
- Machine Learning: Automated model training reduces the need for explicit rules, although human insight is still valuable in data curation and algorithm selection.
-
Adaptability:
- Traditional Programming: Changes in underlying patterns or rules necessitate code modification.
- Machine Learning: Models can adapt to some changes, but continuous monitoring is required, and adaptation isn’t always instantaneous.
-
Transparency:
- Traditional Programming: Generally has explainable, rule-based logic.
- Machine Learning: Some algorithms might be “black boxes,” making it challenging to interpret the reasoning behind specific predictions.
-
Applicability:
- Traditional Programming: Well-suited for tasks with clear, predefined rules.
- Machine Learning: Effective when facing complex problems with abundant data, such as natural language processing or image recognition.
Code Example: “Hello, World!” Programs
Here are the Python code snippets.
Traditional Programming:
def hello_world(): return "Hello, World!" print(hello_world())Machine Learning:
# Import the relevant library from sklearn.linear_model import LinearRegression import numpy as np # Prepare the data X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) y = np.array([2, 3, 4, 5, 6]) # Instantiate the model model = LinearRegression() # Train the model (in this case, it's just fitting the data) model.fit(X, y) # Make a prediction function def ml_hello_world(x): return model.predict(x) # Test the ML prediction print(ml_hello_world([[6]])) # Output: [7.] -
- 2.
Explain the difference between supervised and unsupervised learning.
Answer:Supervised and unsupervised learning are fundamental paradigms in the realm of machine learning, each with its unique approach to handling data.
Supervised Learning
In supervised learning, the algorithm learns from a labeled dataset, where the inputs (features) and the correct outputs (labels) are provided. The goal is to build a model that can make accurate predictions or classifications for unseen data.
Key Characteristics:
- Training with Labels: The algorithm is trained on labeled data, allowing it to learn the relationship between inputs and outputs.
- Performance Evaluation: The model’s predictions are evaluated against the true labels in the training data.
- Tasks: Well-defined tasks such as classification (e.g., spam detection) or regression (e.g., predicting house prices) are common.
Unsupervised Learning
In contrast to supervised learning, unsupervised learning doesn’t rely on labeled data for training. Instead, it focuses on discovering underlying patterns or structures within the data.
Key Characteristics:
- Training without Labels: The algorithm processes unlabeled data, thereby learning structure and patterns inherent to the data itself.
- Performance Evaluation: Since there are no labels, evaluation is often more subjective or based on specific application goals.
- Tasks: Unsupervised methods are often used for data exploration, clustering (grouping similar data points) and dimensionality reduction.
Hybrid Approaches
There also exist learning paradigms that blend aspects of both supervised and unsupervised learning. This approach is known as semi-supervised learning and is particularly useful when labeled data is scarce or expensive to obtain.
- 3.
What is the role of feature selection in machine learning?
Answer:Feature selection plays a crucial role in machine learning, streamlining models for improved performance, interpretability, and efficiency.
Key Considerations
-
Dimensionality Reduction: High-dimensional data can lead to overfitting and computational challenges. Selecting relevant features can mitigate these issues.
-
Model Performance: Extraneous features can introduce noise or redundant information, compromising a model’s predictive power.
-
Interpretability: Selecting a subset of the most important features can often make a model more understandable, especially for non-black box models.
-
Computational Efficiency: Used reduced feature sets can speed up training and prediction times.
Feature Selection Methods
Filter Methods
These methods preprocess data before model building:
- Variance Threshold: Remove low-variance features that offer little discriminatory information.
- Correlation Analysis: Remove one of two highly correlated features to address redundancy.
- Chi-Squared Test: Rank and select features based on their association with the target variable in classification tasks.
Wrapper Methods
These methods evaluate models with different feature subsets, often using a cross-validation strategy:
- Forward Selection: Starts with an empty set and adds features one at a time based on model performance metrics.
- Backward Elimination: Starts with all features and removes them one by one, again based on performance metrics.
- Recursive Feature Elimination (RFE): Uses models like logistic regression that assign weights to features, and eliminates the least important features.
Embedded Methods
These methods incorporate feature selection directly into the model training process:
- Lasso (L1 Regularization): Adds a penalty equivalent to the absolute value of the magnitude of the coefficients, leading to feature selection.
- Tree-Based Selection: Decision trees and their ensembles (e.g., Random Forest, Gradient Boosting Machines) naturally assign feature importances, which can be used for selection.
- Feature Importance from Model Algorithms: Some models, like Random Forest or LightGBM, provide metrics on feature importance, which can be used to select the most relevant features.
-
- 4.
Describe the concept of overfitting and underfitting in machine learning models.
Answer:Overfitting and underfitting are phenomena that arise when training machine learning models.
Overfitting
Overfitting occurs when a model learns the training data too well. As a result, it performs poorly on unseen (test or validation) data. Symptoms of overfitting include high accuracy on the training data but significantly lower accuracy on test data.
This is akin to “memorization” rather than learning from the data’s inherent patterns. Reasons for overfitting include the model being too complex or the training data being insufficient or noisy.
Visual Representation
When you look at a graph, you will notice that the “model’s line wiggles a lot” to try and accommodate most of the data points.
Underfitting
Underfitting happens when a model performs poorly on both the training data and the test data. This occurs because the model is too simple to capture the underlying patterns of the data.
In essence, the model “fails to learn” from the training data. Causes of underfitting often stem from using overly simplistic models for the data at hand or from having an inadequate amount of training data.
Visual Representation
The “model’s line” will be a simple one (like a straight line for linear models) that misses a lot of the data’s intricacies.
Ideal Fitting
The goal in machine learning is to achieve optimal generalization, where a model performs well on both seen and unseen data. This balancing act between overfitting and underfitting is termed “ideal fitting”.
A model that achieves ideal fitting has learned the underlying patterns in the data without memorizing noise or being so inflexible as to miss important trends.
Visual Representation
The “model’s line” follows the data points closely without overemphasizing noise or missing key patterns.
Strategies to Counter Overfitting
- Simplify the Model: Use a simpler model, such as switching from a complex deep learning architecture to a basic decision tree.
- Feature Selection: Choose only the most relevant features and discard noisy or redundant ones.
- Regularization: Add penalties for large coefficients, as in Lasso or Ridge regression.
- Cross-Validation: Use more of the available data for both training and testing, especially in smaller datasets.
- Early Stopping: Halt the training process of models like neural networks as soon as the performance on a validation set starts to degrade.
Code Example: Decision Tree with Limited Depth
Here is the Python code:
from sklearn.tree import DecisionTreeClassifier # Limiting tree depth to 3 dt = DecisionTreeClassifier(max_depth=3)Strategies to Counter Underfitting
- Increase Model Complexity: Use more advanced models that can capture intricate patterns.
- Feature Engineering: Derive new, more informative features from the existing ones.
- More Data: Especially for complex tasks, having a larger dataset can help the model understand underlying patterns better.
- Hyperparameter Tuning: Adjust the settings of the learning algorithm or model to get the best performance.
- Ensemble Methods: Combine predictions from multiple models to improve overall performance.
- 5.
What is cross-validation and why is it important?
Answer:Cross-validation is a robust method for estimating the performance of a machine learning model. Its key advantage over a simple train/test split is that it uses the full dataset for both training and testing, resulting in a more reliable performance metric.
Why Use Cross-Validation Over Train/Test Split?
- Maximizes Dataset Utility: With cross-validation, every data point is used for both training and testing, minimizing information loss.
- More Reliable Performance Estimates: Cross-validation produces multiple performance metrics (such as accuracy or mean squared error), allowing for the calculation of standard deviation and confidence intervals.
- Helps Combat Overfitting: Models consistently performing better on the training set than the test set are likely overfitted, a phenomenon easily detectable with cross-validation.
Common Types of Cross-Validation
- k-Fold Cross-Validation: The dataset is divided into roughly equal-sized folds. The model is trained times, each time using folds as the training set and the remaining fold as the test set.
- Leave-One-Out Cross-Validation (LOOCV): A special case of k-fold cross-validation where equals the number of instances in the dataset. Each individual data point is used as the test set, with the remaining data points used for training.
- Stratified Cross-Validation: Ensures that each fold maintains the same class distribution as the original dataset. This is especially useful for imbalanced datasets.
Code Example: k-Fold Cross-Validation
Here is the Python code:
import numpy as np from sklearn.model_selection import cross_val_score, KFold from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_iris # Load the Iris dataset X, y = load_iris(return_X_y=True) # Create a k-Fold cross-validation splitter kfold = KFold(n_splits=5, shuffle=True, random_state=42) # Initialize a classifier classifier = LogisticRegression() # Perform k-Fold cross-validation cv_scores = cross_val_score(classifier, X, y, cv=kfold) print("Cross-validated accuracy scores:", cv_scores) print("Mean accuracy:", np.mean(cv_scores)) - 6.
Explain the bias-variance tradeoff in machine learning.
Answer:The Bias-Variance Tradeoff is a fundamental concept in machine learning that deals with the interplay between a model’s complexity, its predictive performance, and its generalizability to unseen data.
Sources of Error
When a machine learning model makes predictions, there are several sources of error:
- Bias (Systematic Error): Arises when a model is consistently inaccurate, typically due to oversimplified assumptions.
- Variance (Random Error): Reflects the model’s sensitivity to the training data; a high-variance model can overfit and capture noise.
The tradeoff stems from the fact that as you try to reduce one type of error, the other may increase.
Visual Representation
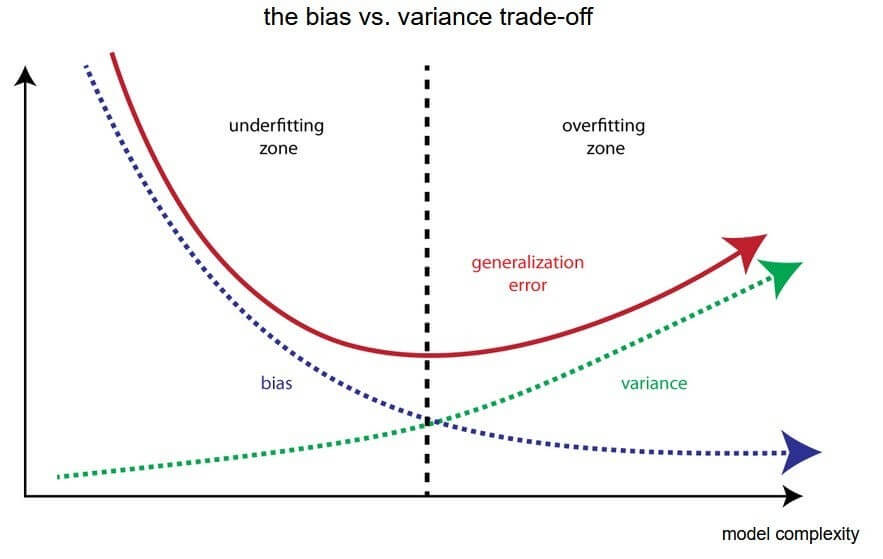
Overfitting and Underfitting
- Overfitting: High model complexity fits the training data too closely and performs poorly on unseen data (high variance).
- Underfitting: The model is too simple to capture the underlying patterns in the data and thus has poor performance on both the training and test data (high bias).
Desired Model Sweet Spot
Aim for a model that generalizes well to new, unseen data:
- Generalization: A model that strikes a good balance between bias and variance will be more robust and have better predictive performance on unseen data.
- Simplicity: Whenever possible, it’s advisable to choose a simpler model that generalizes well.
Strategies to Navigate the Tradeoff
- Cross-Validation: Helps in estimating the model’s performance on new data.
- Learning Curves: Plotting training and validation scores against the size of the training set can provide insights.
- Regularization: Techniques like Lasso or Ridge can help control model complexity.
Code Example: Decision Tree Classifier
Here is the Python code:
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import learning_curve from sklearn.tree import DecisionTreeClassifier # Generate sample data np.random.seed(0) X = np.random.rand(100, 1) y = np.cos(2.5 * np.pi * X).ravel() # Instantiate a decision tree classifier dt = DecisionTreeClassifier() # Compute learning curve scores train_sizes, train_scores, valid_scores = learning_curve(dt, X, y, train_sizes=np.linspace(0.1, 1.0, 10)) # Plot learning curve plt.plot(train_sizes, np.mean(train_scores, axis=1), label='Training Score') plt.plot(train_sizes, np.mean(valid_scores, axis=1), label='Validation Score') plt.xlabel('Training Samples') plt.ylabel('Score') plt.title('Learning Curve') plt.legend() plt.show() - 7.
What is regularization and how does it help prevent overfitting?
Answer:Regularization is a set of techniques used in machine learning to prevent overfitting. It accomplishes this by adding penalties to the model’s loss function, leading to more generalized models. Two common types of regularization are Lasso (L1) and Ridge (L2), each with its unique penalty strategy.
L1 and L2 Regularization
-
L1 regularization adds a penalty proportional to the absolute values of the coefficients. This can lead to sparse models where less important features have a coefficient of zero.
-
L2 regularization squares the coefficients and is known for its tendency to distribute the coefficient values more evenly.
Techniques to Prevent Overfitting
-
Early Stopping: Training is halted when the model’s performance on a validation dataset starts to degrade.
-
Cross-Validation: The dataset is divided into subsets, and the model is trained and validated multiple times, allowing a more robust evaluation.
-
Ensemble Methods: Techniques like bagging and boosting train multiple models and combine their predictions to reduce overfitting.
-
Pruning: Commonly used in decision trees, it involves removing sections of the tree that provide little predictive power.
-
Feature Selection: Choosing only the most relevant features for the model can reduce the chance of overfitting.
-
Data Augmentation: Introducing variations of the existing data can help prevent the model from learning the training data too well.
-
Simpler Algorithms: In some cases, using a less complex model can be more effective, especially when the data is limited.
-
- 8.
Describe the difference between parametric and non-parametric models.
Answer:In statistical modeling, there is a distinction between parametric and non-parametric methods, each with unique strengths and limitations.
Parametric Models
Parametric models make specific assumptions about the data distribution from which the sample is drawn. Once these assumptions are met, parametric models typically offer increased efficiency with simpler and faster computations.
Common parametric models include:
- Linear Regression: Assumes a linear relationship between variables and normal distribution of errors.
- Logistic Regression: Assumes a linear relationship between variables and that errors are independent and follow a binomial distribution.
- Normal Distributions-Based Methods (t-tests, ANOVA): Assume data is normally distributed.
Non-Parametric Models
Non-parametric models, in contrast, make fewer distributional assumptions. They are often more flexible and can be applied in a wider range of situations, at the cost of requiring more data for accurate estimations.
Common non-parametric models include:
- Decision Trees: Segments data into smaller sets, making no distributional assumptions.
- Random Forest: An ensemble method often used for classification and regression tasks that averages multiple decision trees.
- K-Nearest Neighbors: Makes predictions based on similarities to other data points.
- Support Vector Machines (SVM): Effective for classification tasks and doesn’t make strong assumptions about the distribution of the input data.
Hybrid and Semiparametric Models
There is also a middle ground between the parametric and non-parametric extremes. Semiparametric methods combine some of the parametric and non-parametric advantages.
For example, the Cox Proportional Hazards model used in survival analysis combines a parametric model for the baseline hazard (logistic or normal, typically) with a non-parametric model for the effect of the predictors.
Other hybrid models, like the Generalized Additive Model (GAM), introduce non-linear relationships in a parametric framework, offering greater flexibility than purely parametric methods but often with more interpretability than non-parametric approaches.
- 9.
What is the curse of dimensionality and how does it impact machine learning?
Answer:The curse of dimensionality is a phenomenon that arises when working with high-dimensional data, leading to significant challenges in problem-solving, computational efficiency, and generalization for machine learning algorithms.
Key Challenges Arising from High Dimensions
-
Increased Sparsity: As the number of dimensions grows, the volume of the sample space expands rapidly, resulting in sparser data. This may lead to a scarcity of data points, making it difficult for algorithms to identify meaningful patterns or relationships.
-
Data Overfitting: High-dimensional spaces offer more opportunities for chance correlations. Consequently, an algorithm trained on such data is more likely to fit the noise in the dataset, leading to poor performance on unseen data.
-
Computational Hurdles: Many machine learning techniques exhibit an exponential growth in computational requirements as the number of dimensions increases. This can make analysis infeasible or lead to a reliance on limited approximations.
-
Data Redundancy: Paradoxically, while high-dimensional spaces can be sparse, they can also exhibit redundancy. This means that even with a large number of dimensions, some of the information in the data could be duplicated or highly correlated.
-
Feature Selection and Interpretability: In high-dimensional settings, identifying the most relevant features can be challenging. Moreover, as the number of dimensions grows, so does the difficulty of interpreting and understanding the relationships within the data.
-
Increased Sample Size Requirements: To maintain a certain level of statistical confidence in high-dimensional spaces, the required sample size often needs to grow exponentially with the number of dimensions.
Code Example: Curse of Dimensionality Demonstrated with Exponential Growth
Here is the Python code:
import numpy as np import matplotlib.pyplot as plt # Range of dimensions dimensions = np.arange(1, 101) # Number of points for each dimension num_points = 10 # Compute and visualize the growth rate mean_distances = [np.mean(np.linalg.norm(np.random.rand(num_points, dim), axis=1)) for dim in dimensions] plt.plot(dimensions, mean_distances) plt.title('Exponential Growth in Sample Space Volume') plt.yscale('log') plt.show() -
- 10.
Explain the concept of model complexity and its relationship with performance.
Answer:Model complexity refers to how intricate or flexible a machine learning model is in capturing relationships in data. This complexity comes with both advantages and disadvantages in terms of predictive performance and generalizability.
Overfitting: The Pitfall of Over-Complex Models
-
Overfitting happens when a model is excessively complex, capturing noise and small fluctuations in the training data that don’t reflect the true underlying patterns. As a result, the model doesn’t generalize well to new, unseen data.
This can be compared to a student who has memorized the training dataset without understanding the concepts, and then performs poorly on a test that has new questions.
Model Complexity Metrics
Cross-Validation
- K-Fold Cross-Validation: The data is split into K folds; each fold is used as a validation set, and the process is repeated K times, providing an average performance measure.
Learning Curves
- Train-Test Learning Curves: Plots of model performance on the training and test sets as a function of the dataset size can indicate overfitting if the training performance remains high while the test performance plateaus or decreases.
Information Criteria
- AIC and BIC: These metrics, derived from likelihood theory, penalize the number of model parameters. AIC puts a higher penalty, making it more sensitive to overfitting.
Regularization Path
- For models like Lasso and Ridge regression that introduce penalties for model parameters, one can look at how the optimal penalty changes with the strength of regularization.
Balancing Act: Bias vs. Variance
- Bias is the difference between the expected model predictions and the true values.
- Variance is the model’s sensitivity to small fluctuations in the training data.
High model complexity typically leads to low bias but high variance. The challenge is to find a middle ground that minimizes both.
Code Example: AIC and BIC in R
Here is the R code:
# Fit a linear model model <- lm(Sepal.Length ~ ., data = iris) # Calculate AIC and BIC AIC(model) BIC(model) -
Data Preprocessing and Feature Engineering
- 11.
What is data preprocessing and why is it important in machine learning?
Answer:Data preprocessing is a crucial step in machine learning that focuses on cleaning, transforming, and preparing raw data for modeling. High-quality inputs are essential for accurate and reliable outputs.
Key Steps in Data Preprocessing
-
Data Cleaning:
- Identify and handle missing data.
- Remove duplicate records.
- Detect and deal with outliers.
-
Data Integration:
- Merge data from multiple sources.
-
Data Transformation:
- Convert data to appropriate formats (e.g., categorical to numerical).
- Normalize data to a standard scale.
- Discretize continuous attributes.
- Reduce dimensionality.
-
Data Reduction:
- Reduce noise in the data.
- Eliminate redundant features.
- Eliminate correlated features to avoid multicollinearity.
-
Data Discretization:
- Binning or bucketing numerical variables.
- Converting categorical data to numerical form.
-
Feature Engineering:
- Create new features that capture relevant information from the original dataset.
- Feature scaling to ensure all features have equal importance.
-
Feature Selection:
- Identify the most relevant features for the model.
- Eliminate less important or redundant features.
-
Resampling:
- Handle imbalanced classes in the target variable.
Code Example: Handling Missing Data
Here is the Python code:
import pandas as pd # Create a sample DataFrame with missing data data = {'A': [1, 2, None, 4, 5], 'B': ['a', 'b', None, 'c', 'a']} df = pd.DataFrame(data) # Identify and count missing values print(df.isnull().sum()) # Handle missing data (e.g., using mean imputation) mean_A = df['A'].mean() df['A'].fillna(mean_A, inplace=True) # Alternatively, you can drop missing rows: # df.dropna(inplace=True) -
- 12.
Explain the techniques used for handling missing data.
Answer:Handling missing data is a critical part of data analysis. It ensures the accuracy and reliability of analytical results. Let’s look at different strategies to deal with missing data.
Techniques for Handling Missing Data
1. Deletion
-
Listwise Deletion: Eliminates entire rows with any missing values. This method is straightforward but can lead to a significant loss of data.
-
Pairwise Deletion: Analyzes data on a pairwise basis, ignoring missing values. While it preserves more data, the sample sizes for specific comparisons may vary, leading to potential inconsistencies.
-
Column (Feature) Deletion: Removes entire columns with any missing values. This approach is suitable when only a small proportion of values are missing.
2. Data Imputation
- Mean/Median/Mode: Replace missing values with the mean (for normally distributed data), median, or mode of the column. It’s a simple method but can distort relationships and variability.
- Last Observation Carried Forward (LOCF): Common in time series data, it replaces missing values with the most recent non-missing value.
- Linear Interpolation: Estimates missing values based on a line connecting the two closest non-missing values before and after.
- Regression: Predict missing values using other related variables as predictors. It’s a more complex imputation method.
- K-Nearest Neighbors (KNN): Predict missing values based on the values of the nearest neighbors in the feature space.
- Multiple Imputation: Creates several imputed datasets and analyzes them separately before combining the results. It accounts for the uncertainty associated with imputation.
3. Handling During Data Collection
- Standardized Entry Forms: Ensures all necessary fields are filled out.
- Mandatory Fields: Requires specific fields to be completed.
- Database Constraints: Using constraints like “NOT NULL” can prevent missing data at the system level.
4. Advanced Techniques
- Utilize Algorithms: Some machine learning models handle missing data more gracefully, like Random Forests or XGBoost.
- Predictive Models: Building models to predict missing values using non-missing data as features.
- Domain Knowledge: Understanding the reasons behind missing data and making informed decisions based on that knowledge.
-
- 13.
What is feature scaling and why is it necessary?
Answer:Feature scaling is a crucial data preprocessing step for many machine learning algorithms. It standardizes the range of independent variables, ensuring they contribute to model training in a balanced way.
Why Feature Scaling is Necessary
-
Gradient Descent: Many algorithms, such as linear regression, use gradient descent to optimize model parameters. Consistent feature ranges help the algorithm converge more efficiently.
-
Distance-Based Metrics: Algorithms like K-Nearest Neighbors are sensitive to feature magnitudes and can yield biased results without scaling.
-
Model Interpretability: Coefficients in models like logistic regression reflect feature importance relative to one another. Scaled features provide more meaningful coefficients.
-
Equal Algorithm Attention: Unscaled features might dominate the model’s learning process simply because of their larger magnitudes.
Common Scaling Techniques
Min-Max Scaling
- Range: Maps feature values to a range between 0 and 1.
- Use Case: When feature values are uniformly distributed.
Standardization
- Z-Score: Transforms the data to have a mean of 0 and a standard deviation of 1.
- Range: Suitable when data follows a normal distribution.
- Note: Outliers can heavily influence the mean and standard deviation, making this method sensitive to outliers.
Robust Scaling
- Outlier Robustness: Reduces the influence of outliers on the scaled values.
- Use Case: When the dataset contains outliers.
Unit Vector Scaling
- Scale: Transforms the values to have a norm of 1, turning them into vectors on the unit hypersphere.
- Use Case: When only the direction of the data matters, not its magnitude.
Log and Yeo-Johnson Transformations
- Normalization: Useful for features that do not follow a Gaussian distribution.
- Transformation: Maps data to a more normally distributed space.
Mean Normalization
- Adjustment for Mean: Scales the data by subtracting the mean and then dividing by the range.
- Range: Slightly expands the feature space around zero.
-
- 14.
Describe the difference between normalization and standardization.
Answer:Normalization and Standardization
Normalization and Standardization are feature scaling techniques used in data preprocessing to ready data for ML models.
Normalization
Normalization brings data into a specific range, typically .
Standardization
Standardization converts data to have a mean of 0 and a standard deviation of 1.
Mathematical Formulas
- Normalization:
- Standardization:
Key Differences
1. Range of Values
- Normalization: for normalized data.
- Standardization: No fixed range.
2. Role of Outliers
- Normalization: Might distort skewed data in the presence of outliers.
- Standardization: Less prone to outlier influence.
3. Data Interpretation
- Normalization: Data is directly interpretable.
- Standardization: Data is interpretably transformed, useful in certain algorithms, e.g. PCA.
Code Example
Here is the Python code:
import numpy as np def normalize_data(data): return (data - np.min(data)) / (np.max(data) - np.min(data)) def standardize_data(data): return (data - np.mean(data)) / np.std(data) # Generate sample data data = np.array([1, 2, 3, 4, 5]) # Normalize and standardize the data normalized_data = normalize_data(data) standardized_data = standardize_data(data) print("Original Data:", data) print("Normalized Data:", normalized_data) print("Standardized Data:", standardized_data) - 15.
What is one-hot encoding and when is it used?
Answer:One-Hot Encoding is a technique often employed with categorical data to make it compatible for machine learning algorithms that expect numerical input.
How it Works
Say you have a feature like “Color” with three categories: Red, Green, and Blue. You’d create three binary columns – one for each color – where a 1 indicates the presence of that color and 0s the absence.
Red Green Blue 1 0 0 0 1 0 0 0 1 In this way, you convert each categorical entry into a binary vector.
Code Example: One-Hot Encoding
Here is the Python code:
import pandas as pd # Sample data data = {'Color': ['Red', 'Green', 'Blue', 'Blue', 'Red']} df = pd.DataFrame(data) # One-hot encoding one_hot_encoded = pd.get_dummies(df, columns=['Color']) print(one_hot_encoded)Advantages
- Algorithm Compatibility: Most ML algorithms work better with numerical data.
- Category Preservation: Each category remains distinct.
Limitations
- Dimensionality: Can introduce high dimensionality in the data.
- Collinearity: May introduce perfect multicollinearity, where one binary column can be predicted perfectly from the others.
- Memory: Can lead to increased memory usage for large datasets.