
Principal Component Analysis (PCA) is a statistical technique used in the fields of machine learning and data science for dimensionality reduction of large datasets. It involves transforming the data to a new coordinate system in which the first coordinate (the first principal component) explains the largest variation in the data. In technical interviews, PCA-related questions assess a candidate’s understanding of statistics, data preprocessing, and feature extraction. These concepts are fundamental in machine learning and data science, making PCA an essential topic to master for individuals aiming at roles in these fields.
Principal Component Analysis Basics
- 1.
What is Principal Component Analysis (PCA)?
Answer:Principal Component Analysis (PCA) is a popular dimensionality reduction technique, especially useful when you have a high number of correlated features.
By transforming the original features into a new set of non-correlated features, principal components (PCs) , PCA simplifies and speeds up machine learning algorithms such as clustering and regression.
The PCA Process
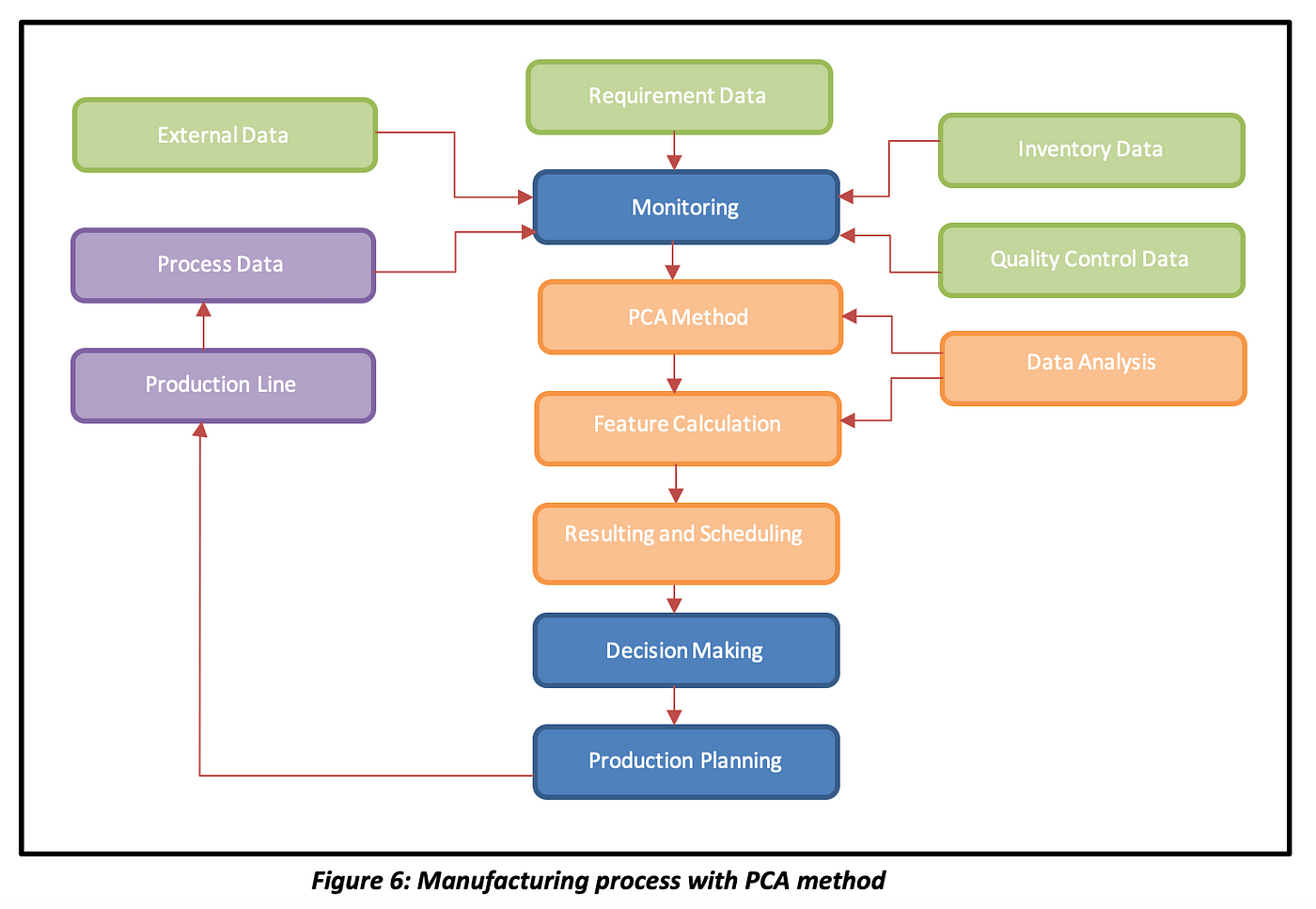
-
Standardization: Depending on the dataset, it might be necessary to standardize the features for better results.
-
Covariance Matrix Calculation: Determine the covariance among features.
-
Eigenvector & Eigenvalue Computation: From the covariance matrix, derive the eigenvectors and eigenvalues that signify the PCs:
- Eigenvectors: These are the directions of the new feature space. They represent the PCs.
- Eigenvalues: The magnitude of the eigenvectors, indicating the amount of variance explained by each PC.
-
Ranking of PCs: Sort the eigenvalues in descending order to identify the most important PCs (those responsible for the most variance).
-
Data Projection: Use the significant eigenvectors to transform the original features into the new feature space.
Variance and Information Loss
PCA aims to retain as much variance in the data as possible. The cumulative explained variance of the top (out of ) PCs gives a measure of the retained information:
Choosing the Right Number of Components
An important step before applying PCA is selecting the number of PCs to retain. Common methods include the “Elbow Method,” Visual Scree Test, and Kaiser-Guttman Criterion.
Code Example: PCA with scikit-learn
Here is the Python code:
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler import pandas as pd # Load data url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" df = pd.read_csv(url, names=['sepal length', 'sepal width', 'petal length', 'petal width', 'target']) # Standardize the Data features = ['sepal length', 'sepal width', 'petal length', 'petal width'] x = df.loc[:, features].values x = StandardScaler().fit_transform(x) # PCA Projection to 2D pca = PCA(n_components=2) principalComponents = pca.fit_transform(x) # Visualize in DataFrame principalDf = pd.DataFrame(data=principalComponents, columns=['PC1', 'PC2']) finalDf = pd.concat([principalDf, df[['target']]], axis=1) -
- 2.
How is PCA used for dimensionality reduction?
Answer:Principal Component Analysis (PCA) is a powerful technique that uses linear algebra to simplify complex datasets, reducing their number of features.
PCA: A Summary
- Data Transformation: PCA projects data onto a lower-dimensional subspace defined by its principal components.
- Orthogonal Components: These unit vectors define the new coordinate system, ensuring each component is uncorrelated with the others.
- Variance Retention: PCA selects components that maximize data variance, ensuring minimal information loss.
Steps of PCA
-
Centering the Data: Subtracting each feature’s mean ensures the dataset is centered.
-
Computing Covariance Matrix: This indicates the degree to which two variables change together.
-
Eigenanalysis: Calculates the eigenvalues and eigenvectors of the covariance matrix.
-
Sorting Eigenpairs: Sorts the eigenvectors based on their corresponding eigenvalues.
-
Creating Projection Matrix: This consists of the top eigenvectors to project data onto a lower-dimensional space.
-
Projecting Data: Multiplies the original data by the projection matrix to obtain the transformed dataset.
The Beauty of PCA
- Interpretability: By examining the feature loadings of principal components, one can often infer the types of patterns these components represent.
- Noise Reduction: Since PCA focuses on components capturing the most variance, it can often suppress components related to noise or irrelevant patterns.
- Financial Analysis: In stock market analysis, PCA can help identify sets of correlated stocks and reduce exposure to risk.
- Image Compression: PCA is leveraged in image compression techniques like eigenfaces and the JPEG format to reduce file size.
- Feature Engineering: By transforming original features into principal components, PCA can assist in feature engineering for machine learning models.
- 3.
Can you explain the concept of eigenvalues and eigenvectors in PCA?
Answer:Principal Component Analysis (PCA) uses eigenvalues and eigenvectors in its underlying linear algebra to transform data into a new coordinate system.
Key Concepts
- Eigenvalues: These represent the magnitudes of variance explained by the correlated input dimensions.
- Eigenvectors: These are the orthogonal axes where the data gets projected to maximize variance.
In PCA, the covariance matrix of the input data is analyzed. This matrix concisely summarizes relationships between all pairs of features.
Eigenvalue Equation
The eigenvalues and eigenvectors of the covariance matrix satisfy the following matrix equation:
Geometrically, this equation corresponds to the transformation of the original dataset by the covariance matrix, after which the resulting vectors are simply scaled by their eigenvalues.
Computation of Eigenvalues and Eigenvectors
-
Covariance Matrix: First, the covariance matrix of the dataset is computed. This is a real and symmetric matrix, which has several useful properties.
-
Characteristic Polynomial: The characteristic polynomial of the covariance matrix is derived. The roots of this polynomial are the eigenvalues of the matrix.
-
Eigenvalue Computation: The eigenvalues are found by solving the characteristic polynomial. There are closed-form expressions for eigenvalues of 2x2 and 3x3 matrices; for higher dimensions, numerical methods are employed.
-
Eigenvector Calculation: For each calculated eigenvalue, the corresponding eigenvector is determined. This typically involves solving a system of linear equations or matrix inversion. Alternatively, one can employ numerical algorithms.
Variance Preservation
PCA aims to maximize variance. This is achieved when the eigenvectors with the largest associated eigenvalues are actioned upon.
The covariance matrix, being symmetric, has real eigenvalues, and its eigenvectors are orthogonal. Such properties ensure the reliability and interpretability of PCA results.
- 4.
Describe the role of the covariance matrix in PCA.
Answer:The covariance matrix is fundamental to understanding PCA. It summarizes the relationships between variables in high-dimensional data, shaping PCA’s ability to discern patterns and reduce dimensionality.
Core Concepts
-
Covariance: Measures the joint variability of two variables. If they tend to increase or decrease together, the covariance is positive; if one tends to increase as the other decreases, the covariance is negative.
-
Covariance Matrix: Describes the covariance relationship between every pair of variables in a dataset. It also encodes the individual variances along its diagonal.
-
Eigenvalues and Eigenvectors of the Covariance Matrix: Their extraction defines the principal components—orthogonal directions that capture the most variance in the data.
Mathematical Representation
For a dataset of samples and dimensions, the covariance matrix is defined as:
where is the mean vector of .
Key Components of the Covariance Matrix
-
Diagonal Elements: Represent the variances of the original features. Larger variances indicate more information content in that dimension.
-
Off-Diagonal Elements: Encode the covariances between feature pairs. If the off-diagonal element is large in magnitude, it suggests a strong relationship between the corresponding features.
Unique Properties
-
Symmetry: For any real-valued dataset, the covariance matrix is symmetric.
-
Positive Semidefiniteness: All eigenvalues of the covariance matrix are non-negative. This reflects the non-negative relationship between original feature variances and the variance they collectively capture in projected dimensions (the principal components).
-
Orthonormal Eigenbasis: The eigenvectors of the covariance matrix (defining the principal components) are both orthogonal and normalized.
-
- 5.
What is the variance explained by a principal component?
Answer:The explained variance of a principal component in PCA is the amount of variance in the original data that is attributed to that specific component.
The explained variance provides a measure of how much information the component contributes in representing the data.
Mathematical Formulation
The explained variance of each principal component, often denoted as , is calculated using its corresponding eigenvalue, , with the formula:
Where:
- is the eigenvalue of the principal component
- represents the sum of all eigenvalues
This formula yields a proportion of the total variance that can be attributed to each principal component.
For example, in a dataset with features, if the eigenvalues are:
Then:
This means that, for instance, the first principal component alone captures half of the total variance in the data.
- 6.
How does scaling of features affect PCA?
Answer:Feature scaling is essential for many machine learning methods, including Principal Component Analysis (PCA).
The Role of Scaling in PCA
PCA aims to find the axes in the data that best represent its variance. Scaling the features ensures that each feature contributes its fair share to the variance calculation.
-
Unscaled Features: Features with larger scales dominate the variance calculations, leading to skewed component axes.
-
Scaled Features: All features contribute equally to variance computations, yielding more balanced component axes.
-
Standardization: Commonly used, it centers data to have a mean of 0 and a standard deviation of 1. It’s particularly useful when data doesn’t follow a Gaussian distribution.
-
Normalizing: Scales data to a fixed range, which can be beneficial when there are distinct maximum and minimum feature values.
Code Example: Effects of Scaling on PCA
Here is the Python code:
import numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler, MinMaxScaler # Generate example data np.random.seed(0) X = np.dot(np.random.rand(2, 2), np.random.randn(2, 200)).T # Apply different scalers scalers = [None, StandardScaler(), MinMaxScaler()] scaled_data = [X if scaler is None else scaler.fit_transform(X) for scaler in scalers] # Apply PCA to scaled and unscaled data pca = PCA(n_components=2) pca_results = [pca.fit(data) for data in scaled_data] fig, axs = plt.subplots(3, 2, figsize=(10, 15)) for i, ax_row in enumerate(axs): for j, ax in enumerate(ax_row): if j == 0: ax.scatter(X[:, 0], X[:, 1], c='b', s=20) if i == 0: ax.set_title('Original Data') else: ax.scatter(scaled_data[i][:, 0], scaled_data[i][:, 1], c='r', s=20) if i == 0: ax.set_title('Scaled Data') if j == 1 and i == 0: ax.text(0.2, 0.8, 'PC1', va='center', ha='center', backgroundcolor='white') ax.text(0.8, 0.2, 'PC2', va='center', ha='center', backgroundcolor='white') if j == 1 and i > 0: ax.set_yticklabels([]) pca = pca_results[i-1] mean, eigenvector = pca.mean_, pca.components_ ax.quiver(mean[0], mean[1], eigenvector[0, 0], eigenvector[0, 1], scale=5, color='k') ax.quiver(mean[0], mean[1], eigenvector[1, 0], eigenvector[1, 1], scale=5, color='k') plt.show() -
- 7.
What is the difference between PCA and Factor Analysis?
Answer:While PCA and Factor Analysis share a common goal of reducing data dimensionality, they have distinct approaches and are best suited to different types of data.
PCA strives to maximize variance in the original data, while Factor Analysis aims to capture shared variance among variables. The choice between the two methods depends on the data and the research questions being addressed.
Choice of Technique
-
PCA: Ideal when the emphasis is on describing the underlying structure in observed variables. It’s a non-theory-driven technique and is often used in exploratory data analysis.
-
Factor Analysis: Suitable when exploring underlying factors thought to be associated with the observed variables. It’s more theory-driven, aiming to identify latent variables that give rise to the observed patterns.
Mathematical Approach
-
PCA: Utilizes the correlation or covariance matrix of the observed variables to derive orthogonal components that best represent the data’s variance.
-
Factor Analysis: Builds on the relationships among observed variables and posits underlying common factors that directly or indirectly account for the observed variance.
Assumptions
-
PCA: Emphasizes on variance explained by linear combinations of variables. Assumptions primarily relate to data structure, like linearity.
-
Factor Analysis: Incorporates the assumption that observed variables are influenced by a smaller number of unobservable, or latent, variables. It’s sensitive to deviations from its specific underlying structure assumptions.
Output Interpretation
-
PCA: Delivers uncorrelated principal components informed by the original variables. The focus is on explaining variance in the observed data.
-
Factor Analysis: Provides insights into the underlying structure by identifying common latent factors that explain the observed variables’ relationships. It can be varimax or promax factor rotation to make factors more interpretable.
Data Type Considerations
-
PCA: Suited for data driven by linear relationships and where metric scales apply.
-
Factor Analysis: Suitable for data driven by latent factors and where multivariate non-normality or ordinal data is present.
Exploratory vs. Confirmatory
-
PCA: Typically used for exploratory data analysis to identify patterns.
-
Factor Analysis: Often employed in confirmatory studies to test or validate previously proposed theoretical constructs or latent variables.
-
- 8.
Why is PCA considered an unsupervised technique?
Answer:Principal Component Analysis (PCA) is an unsupervised learning method that aims to discover the underlying structure in a dataset.
Key Characteristics of PCA
-
No Supervision: The method doesn’t require labeled data. It focuses purely on identifying patterns inherent to input features.
-
Dimensionality Reduction: The primary aim is to reduce feature space, which can be especially valuable in high-dimensional datasets. This reduction typically involves projecting the data into a lower-dimensional space using a set of derived features, termed principal components.
-
Organized Variation Capture: PCA accomplishes dimensionality reduction by emphasizing features that exhibit the most variance. It then uses this variance to appoint the most informative axes to the new coordinate system.
-
Decoupled Features: The method ensures that the new axes in the reduced feature space are orthogonal to one another. This, in turn, enables feature uncorrelation.
-
Key Use-Cases:
- Data Exploration: Visualizing high-dimensional data.
- Noise Reduction: Identifying and discarding less informative features.
- Compression: Compact representation of data.
-
Training-Free: PCA doesn’t undergo a conventional training phase. Once the principal components are derived, they can be used directly to transform other datasets.
Code Example: PCA with scikit-learn
Here is the Python code:
from sklearn.decomposition import PCA # Assuming we have X, a dataset pca = PCA(n_components=2) X_reduced = pca.fit_transform(X) -
Mathematical Foundations
- 9.
Derive the PCA from the optimization perspective, i.e., minimization of reconstruction error.
Answer:Principal Component Analysis (PCA) can be viewed as an optimization problem aiming to minimize reconstruction error.
Objective Function of PCA
The total mean squared error (MSE) is given by:
Minimization of Reconstruction Error
The problem of finding the direction that minimizes is framed as an optimization task.
Optimization Objective
The optimization objective is to find the optimal direction vector that minimizes the mean squared error.
where
Key Optimization Steps
-
Decomposition of Data: Expressing data points in terms of the principal component direction.
-
Error Measurement: Computing the squared projection error.
-
Objective Optimization: Deriving the objective function to minimize the reconstruction error.
Training Algorithm
-
Obtain the covariance matrix of the data.
-
Perform an eigen-decomposition of the covariance matrix to obtain eigenvalues and eigenvectors.
-
Retain the first eigenvectors corresponding to the top eigenvalues.
-
Project the data onto the subspace defined by the retained eigenvectors to obtain the transformed dataset.
-
- 10.
Can you explain the Singular Value Decomposition (SVD) and its relationship with PCA?
Answer:Singular Value Decomposition (SVD) is a foundational matrix decomposition used in various data analysis and machine learning techniques, including Principal Component Analysis (PCA).
Key Mathematical Components
- Input Data: A matrix with dimensions where represents the number of data points, and represents the number of features (attributes).
- Output: Three matrices , , and such that .
SVD Matrices
- is an orthogonal matrix. Its columns are termed left singular vectors.
- is an matrix that is mainly diagonal, containing the singular values in descending order. The off-diagonal elements are zero.
- is the orthogonal matrix whose rows are the right singular vectors.
Relationship with PCA
- SVD is the computational technique underpinning PCA.
- The matrix from SVD is the same as the matrix of principal component loadings produced by PCA.
Step-by-Step Process in Python
Here is the Python code:
import numpy as np # Generating a Sample Data np.random.seed(0) X = np.random.rand(5, 3) # Performing SVD U, S, VT = np.linalg.svd(X, full_matrices=False) # Calculating Principal Components using SVD PCs = VT.T print("Original Data:\n", X) print("\nPrincipal Components (from SVD):\n", PCs)The code computes the SVD of a random data matrix
Xand outputs the matrix of principal components using SVD. This can now be verified by using libraries such as numpy. - 11.
How do you determine the number of principal components to use?
Answer:Selecting the right number of principal components involves finding a balance between model complexity and information loss.
Explained Variance Method
The explained variance ratio, denoted , represents the proportion of the dataset’s variance attributed to each principal component. This method plots the cumulative explained variance and selects the elbow point, which marks a diminishing rate of return.
Code Example:
Here is the Python code:
from sklearn.decomposition import PCA import matplotlib.pyplot as plt # Assuming data is already defined pca = PCA().fit(data) plt.plot(np.cumsum(pca.explained_variance_ratio_)) plt.xlabel('Number of Components') plt.ylabel('Cumulative Explained Variance') plt.show()Kaiser’s Criterion
This approach retains principal components with eigenvalues greater than one, ensuring each component accounts for at least as much variance as a single original feature.
Code Example:
Here is the Python code:
from numpy.linalg import eigvalsh # Assuming cov_mat is the covariance matrix eigenvalues = eigvalsh(cov_mat) # Count eigenvalues greater than 1 num_of_eigenvalues_gt_1 = sum(eigenvalues > 1)Scree Plot
Among the most straightforward techniques, the scree plot visually displays the eigenvalues in descending order. Analysts look for an “elbow” where the curve starts to level off more.
Code Example:
Here is the Python code:
# Assuming eigenvalues is a sorted array of eigenvalues plt.plot(np.arange(1, len(eigenvalues) + 1), eigenvalues, 'bo-', markersize=8) plt.xlabel('Principal Component') plt.ylabel('Eigenvalue') plt.show()Cross-Validation Approach
In certain predictive tasks, the number of principal components might be determined through cross-validation, where the model’s performance is evaluated across different component counts.
Information-Theoretic Techniques
Bayesian Information Criterion (BIC) and Akaike Information Criterion (AIC) assess model goodness of fit, with lower scores indicating better model fit. These metrics are adaptable to PCA and can guide component selection. Their core difference lies in their penalization strategy.
- BIC applies a more stringent penalty, favoring models with fewer components. Its primary use may be related to hypothesis testing, requiring a bonafide zero-component model.
- AIC’s penalty, while milder, still prefers models that are both parsimonious and effective, making it a reasonable, less conservative choice for practical applications.
- 12.
What is meant by ‘loading’ in the context of PCA?
Answer:‘Loading’ in the context of Principal Component Analysis (PCA) refers to the correlation between original features and the principal components.
Calculation
- Loadings are determined using eigenvectors.
- Each eigenvector corresponds to a loading for every original feature, i.e., the correlation between that feature and the principal component.
Code Example: Loadings in PCA
Here is the Python code:
from sklearn.decomposition import PCA import numpy as np # Sample data X = np.array([[1, 2], [3, 1], [4, 6], [3, 4]]) # PCA pca = PCA(n_components=2) pca.fit(X) # Get loadings loadings = pca.components_.T * np.sqrt(pca.explained_variance_) # First principal component print("Loading for feature 1 on first PC:", loadings[0, 0]) print("Loading for feature 2 on first PC:", loadings[1, 0]) # Second principal component print("Loading for feature 1 on second PC:", loadings[0, 1]) print("Loading for feature 2 on second PC:", loadings[1, 1]) - 13.
Explain the process of eigenvalue decomposition in PCA.
Answer:Eigenvalue decomposition, also known as the principal component analysis (PCA), is a powerful method for reducing the dimensionality of data while retaining its critical characteristics.
Key Components of Eigenvalue Decomposition
-
Covariance Matrix: Initial step in PCA, which involves the computation of the covariances between all pairs of variables in the dataset.
-
Characteristics of Covariance Matrix:
- Symmetric: All its off-diagonal elements are mirror images of themselves.
- Positive semi-definite: All its eigenvalues are non-negative.
Eigenvalue and Eigenvector Calculation
The eigenvectors are what determine the principal directions of the variation in the data. The eigenvalues show the magnitude of variance in these directions.
-
Covariance Calculation:
-
Covariance Matrix Representation:
In the context of PCA, each eigenpair (, ) for the matrix satisfies the following relationship:
Where is the eigenvector, and is the corresponding eigenvalue.
A clear understanding of eigenvector calculations reveals the primary axes and the data’s associated variance—those with higher eigenvalues harboring more significant variability.
Dissecting the Covariance Matrix
The functionality of the covariance matrix is centered around accurately depicting the relationships among multiple variables.
Univariate Example
For two variables, x and y:
Bivariate Example
For three variables, x, y, and z:
In a bivariate scenario, the off-diagonal elements signify the covariance between the corresponding variable pairs.
Code Example: Covariance Matrix Calculation and Eigenpair Computation
Here is a Python code:
import numpy as np # Sample data data = np.array([[1, 3, 5], [5, 4, 2], [7, 6, 3], [8, 7, 4], [3, 7, 9]]) # Centering the data mean_vec = np.mean(data, axis=0) data -= mean_vec # Covariance matrix cov_matrix = np.cov(data, rowvar=False) # Eigen decomposition eigenvalues, eigenvectors = np.linalg.eig(cov_matrix) -
- 14.
Discuss the importance of the trace of a matrix in the context of PCA.
Answer:In the context of principal component analysis (PCA), the trace of a covariance matrix plays a key role in capturing variances and trackable information within data matrices.
The Trace of a Matrix
The trace of a matrix is the sum of its diagonal entries:
Visualized in 2D, the trace corresponds to the sum of the variances along orthogonal directions, depicted by the sum of the squared semi-axes of an ellipse.
Geometric Intuition
In the PCA context, data variance is associated with the eigenvalues of the covariance matrix. The variance in each principal component direction is given by:
where is the eigenvalue for the associated eigenvector , is the number of dimensions, and is the covariance matrix.
Mathematical Background
The covariance matrix, , is real, symmetric, and positive semi-definite. Such matrices have real eigenvalues and orthonormal sets of eigenvectors.
The spectral theorem further states that any real, symmetric matrix can be decomposed as:
where is an orthonormal matrix composed of the eigenvectors, and is a diagonal matrix of the corresponding eigenvalues.
Utilizing the Spectral Theorem
From the spectral decomposition:
and since the trace is invariant to cyclic permutations, it simplifies to:
which is the sum of its diagonal elements, or the sum of its eigenvalues.
Enhanced Scree Plot
If you visualize the eigenvalues, cumulatively, over the total variance (or traces), it provides an enhanced scree plot that assists in the selection of the optimal number of principal components to retain, enriching the visualization with quantifiable insights.
This method is chosen less often than the traditional scree plot; however, it can be valuable, particularly in high-dimensional datasets.
PCA in Practice
- 15.
What are the limitations of PCA when it comes to handling non-linear relationships?
Answer:While Principal Component Analysis (PCA) is an exceptional tool for understanding linear relationships between variables, it has limitations when it comes to non-linear data.
Limitations of PCA with Non-Linear Data
-
Oversimplification: PCA is based on linear transformations, potentially overlooking underlying non-linear structures in the data.
-
Information Loss: PCA might obscure intrinsic data characteristics, especially when significant non-linearity is present.
-
Distinct Projections: Data projections onto the linear subspaces chosen by PCA might not capture the full non-linear richness.
-
Violations of Gaussian Assumptions: PCA operates under the assumption of Gaussian data distributions, which can be problematic for non-linear data distributions such as those with multimodal peaks.
-
Need for Non-Linear Techniques: When data comprises complex, non-linear interactions, linear methods like PCA can be inadequate.
Addressing Non-Linearity with Advanced Techniques
Kernel PCA (kPCA)
- Utilizes a kernel trick to transform the data into a high-dimensional space where non-linear relationships become linear.
- By doing so, it enables PCA to uncover non-linear structures in the data.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Focuses on reducing dimensionality while preserving local, non-linear relationships.
- Especially effective for visualizing clusters in high-dimensional data.
Autoencoders
- Neural network-based techniques that approximate the non-linear identity function, offering advantages in learning non-linear data structures effectively.
Non-Negative Matrix Factorization (NMF)
- Appropriate when data is non-negative, like in image recognition tasks.
- Decomposes a data matrix into non-negative components, making it an effective choice for non-negative, non-linear feature extraction.
Isomap
- Utilizes geodesic distances in the non-linear manifold to build similarity matrices for dimensionality reduction.
- Particularly beneficial for data organized into low-dimensional structures, such as curves or surfaces.
-